

Raft Consensus in 2,000 words
Understanding the Understandable Consensus Protocol


Consensus is when multiple servers join forces to keep a single system running.
Many people are confused about the need for distributed systems. Why do it, when a single machine nowadays is twice as powerful as a few years ago, and will be twice as powerful in a few years?
Because machines can go down. And without any sort of backup, your whole system goes down with it.
The downside, of course, is that multiple machines are hard to keep consistent. One of them may have saved some data, but in the process of replicating it (that is, sending a copy to the others), it may suddenly crash, and that data is now lost, or inaccessible. And without that piece of data, you find yourself, not with a system that’s down, but with one that gives wrong answers.
That’s what consensus is meant to solve: it’s a way to ensure continued service, in a way that’s more scalable and less wasteful than simply having an idle backup “just in case”. Consensus algorithms allow a collection of machines to behave as a coherent whole, and is robust to some of those machines going down, or getting disconnected.
Raft is one of such algorithms.
This week is an interlude from the From Stock Markets to Ledgers series, where I’m going to explain how the Raft consensus algorithm works in around 2,000 words. You can find the paper here if you want to dive deeper, but my goal is to prove to you that consensus is easier to understand than you think, and that it requires no special background to understand it fully.
Let’s dive in.
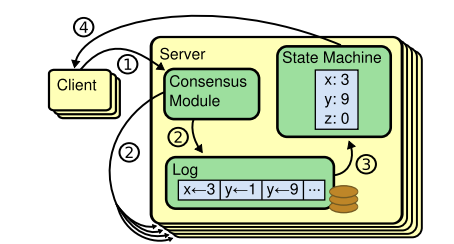
Replicated State Machines
Consensus is typically implemented in the context of replicated state machines. This setup divides each server’s code into three parts: a state machine, a log, and a consensus module. The state machine is deterministic, in the sense that it’s guaranteed that it produces the same output when given the same commands in the same order.
From the outside, you can’t access this machine directly; what you can only do is add entries to the log, labeled with a consecutive integer called index, containing the commands that eventually get applied to the state machine. Think of commands as SQL INSERT queries, and the state machine as a plain relational database.
This setup has one obvious goal: since the state machine is deterministic, the consensus module only has to keep all the logs across servers with the same data in the same order, so that all state machines produce the same output.
Log Replication and Commit
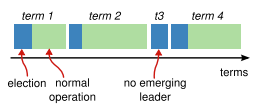
Unlike other consensus protocols, Raft relies on randomly electing one of the servers as the leader, and letting it take control of the replication process for as long as it stays up, and manages to keep communicating with the other servers, who act as followers. This period of time is called a term, and each term gets assigned a consecutive integer.
The leader accepts requests from clients, stores entries on its log, and replicates those entries to the followers via AppendEntries RPC messages. As long as the majority is aware, the leader is allowed to do anything.
There are 4 possible scenarios that the leader needs to handle to replicate the data correctly to each follower:
- The follower’s log is missing some entries
- The follower’s log is the same
- The follower’s log has past entries that are inconsistent
- The follower’s log has future entries that are inconsistent
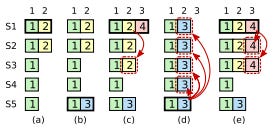
The follower will apply all the missing entries from the list of entries provided in the AppendEntries message, and won’t do anything if it’s already in sync.
But what happens if the follower’s log has entries, past or future, that aren’t in the leader’s log? This can happen when a previous leader replicated some entries, but crashed before finishing the process completely.
In that case, the follower guides the leader so that it sends the entries it needs.
At the beginning of the term, the new leader has no idea which followers are behind, or inconsistent. So it assumes that all followers are in sync until proven otherwise, and figures that out by induction.
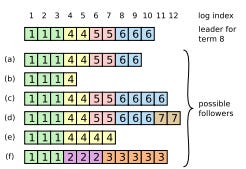
Induction means that the leader keeps track of the index of the entry it needs to send to each follower. These flags get initialized with the index of the leader’s last entry, plus one. The leader then starts sending AppendEntries to each follower, including this flag in the message, and the term of the entry represented by that index.
Assuming that every log is already consistent, the follower must already have an entry with that index and term. If it doesn’t, then that assumption is wrong, and at some point, the follower’s log deviated from the current leader’s.
No problem: the follower can send an error to the leader, and the leader only needs to decrement the index of the entry it needs to send that follower, and try again. Eventually, the follower will receive an index and term that match an entry in its log, and this induction process guarantees that it is the last entry where follower and leader had exact same logs. What the follower needs to do at this point is simply to append all the leader’s entries from that point forward to ensure consistency.
If there are future entries already, the follower will overwrite them. So, when the leader receives a successful response from the follower, it can reset the index flag to its log’s last entry again, now knowing that this particular follower has a log matching its own.
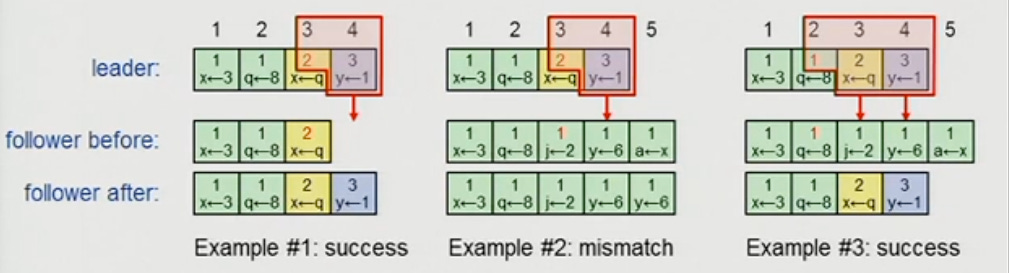
The leader must now make sure that at least the majority of servers have replicated logs. Only then, the leader can commit entries on its own state machine. It uses an approach very similar to a two-phase commit:
Replicates an entry to the majority, using the followers’ responses to guide the process.
Once it has confirmed that a majority of followers match its log up to that entry, the leader commits the entry, while keeping track of the last committed entry with a flag.
The leader lets all servers know in all future messages that this particular entry has been committed by sending the last committed entry index.
Upon receiving that message, followers with matching logs will commit that entry on their own state machines.
Leader Append-Only, State Machine Safety and Leader Completeness
Once an entry has been committed, Raft guarantees that no future leader will be able to overwrite it. And it does so by making sure that all elected leaders have all committed entries.
Every time a leader goes down, Raft is designed to end the term, and randomly choose another leader. But choosing a leader randomly opens a can of worms: can more than one leader get elected? Can a follower without the latest data become leader and force everyone else to be consistent with an inaccurate log?
Let’s look at each problem one by one.
One Leader Only
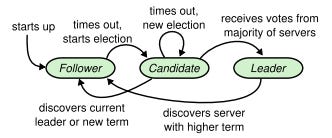
A follower remains a follower as long as it receives messages from the leader within a period called election timeout.
As I mentioned earlier, leaders communicate with followers with AppendEntries. But if there are no new entries to append, the leader is expected to keep sending them with empty lists of entries. These messages are called heartbeats.
So, as long as followers keep getting heartbeats, the leader will remain leader.
But let’s say the leader gets disconnected, and is incapable of sending heartbeats to the cluster. One of the followers eventually times out, and becomes a candidate.
For reasons we’re about to see, the candidate waits another election timeout, and then begins an election. It increases its own stored term, and kicks things off by sending RequestVote messages (another RPC) to all other servers.
Followers vote candidates on a first-come-first-served basis. And when a candidate receives successful RequestVote responses from the majority, it becomes the leader of the new term.
This new leader immediately sends heartbeats to the other servers, both to keep them from timing out, and to make them acknowledge it as leader. Candidates and leaders who have become stale will receive an AppendEntries message with a term equal or higher than the one they store, proving to them that another leader has been elected, and turning them into followers.
What happens when there’s two or more candidates gathering enough votes so that no one can reach a majority? In that case, there’s a split vote, and the term ends without a leader. Election timeouts are somewhat random, and that prevents a thundering-herd-like situation where multiple candidates prevent each other from gathering enough votes one election after another. Eventually, one candidate will time out ahead of the rest, and will be granted the votes of the majority.
Leader Completeness and State Machine Safety
Can a candidate without the latest committed data win an election? No. But that doesn’t mean that the candidate with the largest log becomes the leader. Followers do grant votes to the candidate who first reaches them, but with a caveat: the candidate’s log must be more up-to-date.
By up-to-date, I mean that the follower will grant its vote only if the candidate’s last entry term (included in the RequestVote) is higher, or the candidate’s last entry index (also included) is higher for the same term. If the candidate’s log isn’t more up-to-date than the follower’s, the latter won’t grant its vote.
This, plus the candidate being required to gather the votes of the majority, plus the fact that committed entries have already been replicated to the majority, guarantees that the elected leader will have at least all committed entries. And, since only the leader can commit and tell others to commit, it also guarantees that once an entry gets applied to the state machine, there won’t be any change up to that entry in the replicated state.
Therefore, while leader election depends on timing (elections started a little bit earlier or a little bit later may elect different leaders), safety does not. An entry that gets replicated might not get committed because the leader crashes at the worst time possible, and the new leader may overwrite those entries already replicated. But an entry that gets committed stays committed.
Scaling out
What if I’m scaling out the cluster? Can the new servers elect a new leader in parallel and defeat all these guarantees?
Being a cluster of independent servers, we can’t coordinate all of them to change configuration at once (if we could, there would be no need for consensus in the first place). Therefore, we have to assume that the old and the new configuration must coexist at some point. And Raft must prevent that from becoming problematic.
Raft approaches scaling out in two phases, leveraging the fact that leaders are guaranteed to include all committed entries in their logs. When there’s a configuration change, the leader creates a special log entry for an intermediate configuration called joint consensus. Configuration entries are special because servers apply them regardless of whether they’re committed or not. As soon as a server appends one of those entries in the system, it becomes its new setup right away.
While the new followers are getting up to speed, they’re considered non-voters, and don’t count for the purposes of electing new leaders and considering an entry replicated or committed. This ensures that the joint consensus configuration entry gets replicated fast, and eventually gets committed by a leader.
Once the joint consensus setup is committed, new leaders will be guaranteed to have that entry in that log, acting as a checkpoint in the scaling out process. The leader, then, creates another configuration entry with the new setup, and starts replicating it. Just like appending entries normally, this process is safe against leader crashes, because in the worst case, the new leader will at least have the joint consensus setup. Once a leader commits the new configuration entry, the scaling out process will be complete.
There are two important caveats. One is that, if the leader doesn’t belong in the new cluster configuration, it is meant to become a follower and shut down as soon as the new configuration entry is committed, and the setup is robust to leader crashes.
The other is that followers who belong to the old configuration may time out before getting shut down, and start an election process with RequestVote messages that servers in the new configuration may receive. That’s what the waiting period after timing out was for: followers who haven’t timed out yet are meant to reject RequestVote messages. By waiting an extra election timeout, candidates ensure that followers start timing out and are able to grant votes, ensuring that only candidates in the latest configuration can be granted votes.
Minimizing Latency
You’ve probably noticed that two of the biggest decisions in Raft are choosing the right election timeout, and choosing the right number of servers. Raft performance is similar to other consensus algorithms, but having to ensure that entries are committed before being able to deliver a response to the client heavily depends on how long it takes an RPC message to reach their destination (broadcast time). And, while parallelizing them can improve the latency of the cluster, you can only do so much.
The shorter the election timeout is, the shorter it takes for a stale leader to be deposed, ensuring that clients get quick responses from available leaders. But make it too short, and the increased frequency of elections will tank the response time, because a new leader will have to emerge in order to keep the system responsive.
In practice, the broadcast time should be an order of magnitude less than the election time so that leaders can reliably send heartbeats.
And, typically, a cluster of 5 servers is enough, allowing the system to tolerate up to two failures.
Understandable Consensus
Raft is simple and strong.
Consensus algorithms make sure that a cluster of machines can act as a unified, reliable system, even in the face of crashes and disconnections. Its simplicity comes from the fact that a strong leader gives a unified perspective of the consensus process, and clear rules for log replication and leader election have scope for making normal operations run smoothly, and for making inconsistencies go away.
I haven’t talked about how read-only requests (no entries to add) are handled, or how followers create snapshots to accelerate the replication process and improve performance. And I haven’t formally proved the safety of this algorithm. But you can find out all of that in the Raft paper.
Or, if you like to tinker with it and see it in action, here’s a Raft cluster running on your browser.
This has been The Payments Engineer Playbook. I’ll see you next week.