

If Amazon Can't Figure Out How To Make Money From Blockchain Databases, Nobody Can
Amazon is sunsetting QLDB; if you're a user, your only remaining option is to build it.

They just keep repeating, ‘go faster than any man in the history of space travel’. Like that’s a good thing. Like it would distract me from how insane their plan is. Yeah, ‘you have to go faster than any man in the history of space travel’. Because you’re launching me in a convertible. […]
Physicists, when describing things like acceleration, do not use the word ‘fast’. They’re only doing that in the hopes that I don’t raise any objections to this lunacy. Because I like the way ‘fastest man in the history of space travel’ sounds.
I do like the way it sounds. I like it a lot.
— The Martian (2015)
QLDB, RIP.
On the 31st of July, 2025, AWS is shutting down Quantum Ledger Database. If you were curious, you can’t sign up anymore. And if you were a user, your data will disappear the next day.
QLDB is going away completely.
This is worse than it sounds. The whole point of QLDB was its guarantee of integrity: the data was promised to remain where it was created, in the exact way it was at that moment. Now, by the act of moving it somewhere, that guarantee is simply lost.
Which is why migrating to another DBaaS is not viable. You trusted AWS with your most precious data, and that trust has evaporated. If you need what QLDB gave you, you can’t buy it from a vendor; you have to build it yourself.
As a result, understanding how to build ledgers has never been more valuable.
That’s why, in this special edition of The Payments Engineer Playbook, we’re going to dive deep, like really deep, into the basics of QLDB. So that you may be able to build it.
I’m stranded on Mars
Like most kids growing up I wanted to be an astronaut.
I was fascinated with space, with flying to Mars and beyond, and with grokking the secrets of the Universe. At 12 or so, my father gave me a book called A Short History of Nearly Everything, which covered astronomy, among other scientific areas, in as much detail as 12-year-old me could comprehend.
I read it, and like it happens to all the books I thoroughly enjoy, then and now, I reread it a million times.
Until I no longer wanted to be an astronaut.
Being in space, though one of the most amazing things you can do with your time, is also one of the most dangerous. There, you’re not protected from life-threatening radiation, you’re not kept close to the ground by gravity, and you’re unable to breathe without an oxygen tank.
In space, you’re on your own, in the deepest sense of the word.
I’m not improvising anything. I’m following a script sent by NASA, which was set up to make things as easy as possible. Sometimes I miss the days when I made all the decisions myself. Then I shake it off and remember I’m infinitely better off with a bunch of geniuses deciding what I do than I am making shit up as I go along.
— Andy Weir, The Martian
If you’re screwed in space, you’re very screwed.
And like Mark Watney in The Martian, your only chance is to make the most of your expertise, and the technology around you. To make the necessary tradeoffs to un-screw yourself, and get back home.
Which, incidentally, brings me back to QLDB.
QLDB is like that vandalized rocket that Mark uses to take off from Mars and onto the spaceship that would bring him home. If postgreSQL is a fully fledged spacecraft, a BMW of luxurious interplanetary travel, with all the amenities and guarantees, QLDB is stripped from control panels, from backup systems, and all that doesn’t move the system closer to achieving its mission.
To boldly go where no database has gone before.
Serializability, Integrity, Verifiability, At Scale
QLDB provides a seemingly incompatible set of guarantees on the data stored, at scale:
Integrity, or the guarantee that the data stays where it was created, and is never modified.
Cryptographically verifiability, or the guarantee that you have the means to independently prove the integrity of the data.
Serializability, or the guarantee that reads on the data take into account all previous writes.
Integrity
QLDB isn’t just immutable, because even in the strictest sense, immutable doesn’t prevent a full replacement of its data, or an undocumented mechanism to modify its contents (data is, after all, electrons on exotic materials). QLDB is built in such a way so that there is no way to game it.
In QLDB, if data has been tampered, you will know it.
The history of the data stored is archived, auditable, and accurate.
Verifiability
The only real guarantee of integrity is checking it yourself.
There are two components to prove the integrity of the data stored in QLDB. A one way function, and a verification data structure.
We’ve discussed one way functions before:
Public-key cryptography relies on mathematical problems that are intractable. These are problems that, to our best knowledge, there is no alternative to brute force to solve them.
This is a useful property if we don’t want others to decode our secrets. However, that’s not enough: we want the recipient to be able to decode what others can’t.
This paradox gets resolved because there’s a subset of intractable problems, called one-way functions, which are intractable to solve, but whose solution is easy to verify.

In QLDB, the one-way function (SHA-256) is used to produce hashes from the data. But the crucial component to the data verifiability, and in turn its integrity, is the Merkle tree.
If I asked you to make sure that the changes on a database are accurate, how would you go about it?
Knowing that checksums are used to verify data integrity, what you can do is store hashes for all the changes, just like commits in git, and check them one by one until you reach the end.
However, while this process does work, it doesn’t scale. Your database is meant to have millions of changes applied, and checking all of them each time is very resource intensive.
So, similar to how sorting a list makes binary search possible, there’s a data structure that makes this process of verification more efficient. It’s called Merkle tree.
A Merkle tree is a binary tree where the leaf nodes contain the hashes of all the revisions in the database, sequentially, and the inner nodes contain, recursively, the hashes of those stored one level below them.
I despise diagrams but I see no way around showing you one, so here it is:
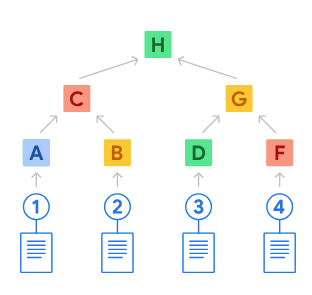
The numbers at the bottom represent a diff of the database, so to say, produced as a result of creating a transaction. The letters right above them are the hash representation of those diffs, the “commit hashes”. The letters right above them are hashes on the hashes, and so on.
The H on top is the root node, and in QLDB it’s called digest.
The verification process, rather than checking A, B, D and F, goes like this. Say you want to check the inclusion of record 4. What you have to do is this:
Calculate the hash of 4, which will be F.
Request QLDB “the proof”, which is a list of hashes that contain C and D.
Calculate the hash of D concatenated with F to obtain G.
And finally, calculate the hash of C concatenated with G to obtain H.
See how AWS or Transparency.dev explain this process if you want to learn more.
The hash function is known; there are sites that calculate it for you for free. The digest is known and available at all times. And the proof can’t be reversed engineered, because one-way functions work precisely against that process.
You don’t have to trust AWS, or me, or anybody. Integrity means that you don’t trust.
You verify.
Serializability
Ledgers, if you recall from Tale of Two Ledgers, operate in two modes. They’re either Recording, when they act as a warehouse of past financial transactions created elsewhere, or Authorizing, when they act as the gatekeeper of all movements of money in the company.
A recording ledger is highly available; an authorizing ledger is strongly consistent.

QLDB is meant to be both.
You see, when you create a transaction on QLDB, it isn’t processed immediately. The transaction is wrapped in a block, and waits its turn in a queue.
The good thing about QLDB though is that it locks optimistically. That’s how it provides high availability.
But a ledger that’s optimistically locked is prone to hot accounts at write time. If a particular account is continually updated, some transactions will fail. QLDB accommodates for this by retrying them.
That’s why QLDB transactions must be idempotent. Not only because the database is append-only, and therefore you have to avoid introducing incorrect entries, but also because you have to make sure that transactions don’t rely on a particular state of the database at a particular point in time to be correct.
Idempotency is a way to decouple entries from the moment they’re committed.
Check the article below if you need to refresh how ledgers work

Stream everything for the full experience
SQL? Gone. Settle down for a subset called PartiQL.
JSON? Gone. Settle down for a subset called Ion.
QLDB does away with everything that’s on the way to its difficult goal.
Here’s the QLDB catch: you can’t use it alone. You’re functionally very restricted, because the whole database is built to achieve verifiable integrity and serializability at scale.
It’s a convertible that you can’t drive.
In practice, you collect the events produced by the database, and you rebuild the data in a normal, relational database elsewhere. If the data in QLDB is different from what you have elsewhere, then ‘elsewhere’ is wrong.
But elsewhere can JOIN, ORDER BY and INTERSECT, and those are nice things to have.
QLDB provides three kinds of events, Control, Revision and Block, that signal specific changes made into the database, and provide specific information about those changes. So that you can channel those events outside, say with Kinesis, into a real database of sorts, and build a materialized view of your ledger.
You get to have the best of both worlds. Auditors at financial institutions would have been very happy about it. If any financial institution used QLDB.
I wish my bank ran on a blockchain database
Money is QLDB’s ultimate case study. For money is the most tempting number to change in one’s own benefit. The most defrauded. The most laundered.
However, no financial institution that I know of relies on an immutable, cryptographically verifiable and strongly consistent database to keep track of its customers’ money.
What they always do is put themselves at the mercy of regulators. Because even if it’s tough and expensive to follow compliance, it’s worth it if it keeps new waves of competition from appearing into the scene.
The failure of QLDB is the success of regulatory capture.
Regulation is the friend of the incumbent.
— 2,851 Miles, Bill Gurley
I wish my bank ran on a blockchain database. I wish we never had to witness another financial institution laundering money for drug cartels (HSBC), or miscalculating the value of its holdings (SVB), or simply losing track of what belongs to whom (Synapse).
We might not need them, but we won’t have blockchain databases if we don’t build them ourselves. If Amazon can’t keep the lights of its blockchain database division open, nobody can.
But that doesn’t mean that you don’t get to have one. Amazon has proven that buying a blockchain database is not a long term option.
You will have to build it instead.
I’ve drawn from many sources to put this article together. Fragment co-founder Omi Chowdhury has a QLDB deep dive that’s very worth it, and Mike Lehan from StuRents.com has another one. Surprisingly, the AWS developer guide on QLDB is wonderfully thorough; specifically, its section on Data Verification is very insightful. There’s also an alternative QLDB Guide by the AWS South Wales User Group. And if you want to play around with a Merkle tree to deepen your understanding of cryptographic verification, the guys at transparency.dev have an illustrated example.
Make sure you share this email with someone who needs to read it.
This has been The Payments Engineer Playbook, I’ll see you next week.